How I Learned to Rap in 4 Languages I don’t speak in 1 Night Using the Free Application “Audacity”
Full disclosure: This post contains affiliate links. ?
Check out this video! Idahosa is back once again for another guest post about using rap to learn a language, and this time he's bringing this absolutely amazing demonstration, where you can hear him rap in eight languages, four of which he doesn't even speak!
Cool as it is, he has broken down the key steps he went through to rap the parts of the song where he was singing in these as-yet-unknown languages, using a really cool and completely free cross-platform application called Audacity.
While I take my hat off to him in terms of his fantastic music, editing and synchronisation skills in the video, his straightforward explanation has me seriously looking into doing some rapping over the next month to help me improve my as-of-yet not fluent and quite choppy Mandarin. I honestly feel like I could personally rap in Japanese (which I don't speak at all) in just a couple of hours after reading this post and his useful audio samples for that language segment of the video!
Have a read and you'll see that rapping like a native (and thus sounding more like one when you speak) isn't as far off as you once thought!
In my last guest post, I discussed the benefits of freestyle rap training as a language learning activity. I'm sure many of you read that post and thought: “Sounds cool…but I'll sure as hell never be able to do that.” If that was your mentality, you'll probably think the same way after watching my “Flow Anthem” video (above). That's why I am writing this current post – I aim to prove to you that nothing I did in the above video is beyond your capabilities.
The Question
As I explain in this video about The Mimic Method Approach and Technique, your primary goal as a language learner should be to master the sound patterns, or “Flow,” of your target language. With the “Flow” down, you can effortlessly mimic native speech sounds and attach meanings to them as you accumulate more target-language experiences.
Foreign language mimicry, however, is challenging. In normal human conversation, we produce and process an average of 25-30 distinct speech sounds per second! For our native language(s), we already have phonetic infrastructure in place to process these sounds without thinking about it (what I would call fluency), but since each language has its own “Flow”, our native language infrastructure is of little use to us when dealing with foreign speech.
So assuming that your goal is oral-fluency, the question you have to ask yourself is this:
“How can I learn to hear and speak foreign speech without having to think about it?”
The Traditional Answer: Leximania
No it's not a real word (at least not yet), I just coined it now to make the point that I'm about to make. “Lexi-” means “of or pertaining to words,” and “-mania” means “obsession.” So “Leximania” refers to “an obsession with words.”
When it comes to language-learning, everyone is a Leximaniac.
Everyone approaches the foreign speech problem through words. It seems like a good idea. Normal speech is too fast, so why not break it down word for word and learn each word individually? But as I explained in my post on The Flow of Fluency, words are unreliable language learning tools. Depending on context, a given word's pronunciation will vary A LOT.
This is why so many language-learners complain about not being able to recognize words in normal, connected speech despite having a substantial vocabulary knowledge. What these learners fail to appreciate is that knowing what a word means is not the same thing as knowing how to use it (see wikipedia articles on the difference between Declarative Knowledge and Procedural Knowledge).
Leximania in language-learning is actually just a byproduct of our society's pandemic what-a-mania. When we encounter something unknown, we must to figure out what it is. So for unknown languages, we turn to textbooks that explain all the whats of the language. But language acquisition isn't a “what” activity; it's a “how” activity. Indeed, nobody learns what to speak English; they learn how to speak English.
Similarly, we don't learn what to ride a bike but rather how to ride a bike, and no one learned how to ride a bike from reading a book. The only way to learn is to hop on that baby and start pedalin'.
The Mimic Method Answer: Phonomania
I'll admit to being very what-a-manic about certain things, but when it comes to learning languages, I'm a die-hard Phonomaniac (“Phono” meaning “sound). In fact, I'll go ahead and distance myself even further from the Leximaniacs by spelling the word more phonetically from here on out — “Fonomeniak”.
We Fonomeniaks care little about words and grammar. Our only goal is to master the target-language's sound system, or “Flow”. We do this by looking closely at the sounds of natural speech (not the discombobulated word-for-word speech that Leximaniacs love). Since the goal is to NOT have to think, we practice training our mouths and ears to hear and recreate these sounds automatically.
You could learn the Flow bit by bit starting with simple phrases, but there's really no reason to dilly-dally with baby talk and Dr. Seuss poems. If you want to master the Flow as quickly as possible, you need to dive right in to the the most phonetically complex form of speech – Rap.
Think about that crazy kid on your block growing up who was already popping wheelies within a week of getting his first bike. He wasn't a bicycle savant or anything, he just didn't care about busting his knees and elbows. His willingness to learn the most difficult skills right from the outset turbo-accelerated his learning curve. So by the time you were finally getting your training wheels taken off, he was already riding with no hands and waving at that girl across the street you always had a crush on. That's why I am a strong advocate of learning to rap in your target-language, whether you've been studying for years or just getting started.
People perceive rapping in a second language as extremely difficult, but you can learn it just as easily as any other motor skill. Like the Idahosa quartet explains in “The Flow Anthem”, all you have to do is:
“…take the sound, break it down – rhythmic, phonetic. You learn the syllables separate, and then connect them together; what you get is…”
Rhythmic Phonetic Training With Audacity
Audacity is a free and open-source audio editor. It is also the Fonemaniaks ultimate language-learning tool. While the Lexomaniac uses the written word to examine the imaginary components of speech (the words), the Fonomeniak uses Audacity to examine the real components of speech (the sounds).
In the sections below, I'll show you how to use Audacity to teach yourself to sing song lyrics with a near-perfect accent. With these techniques, I was able to teach myself all the foreign language lyrics in the second verse of “The Flow Anthem” in a total of 2 hours. Note: I still do not know what these lyrics mean, nor do I care (another symptom of Fonomeniak).
The Basics
You can download Audacity for free here and install it on your computer's hard drive. When you open Audacity, you will see a blank grey workspace and a tool bar at the top.
If you click file–> import –> audio, you can browse your computer for the audio file of the song you want to learn. In this case, I'll start with the Japanese song I learned: “Neittaya”.
As you can see in the screenshot below, the audio data is displayed visually as sound wave, with the horizontal axis representing time, and the vertical axis representing amplitude (loudness). It might look very technical at first, but after some fooling around you'll get used to the interface and find editing the audio as intuitive as editing text on a word processor.
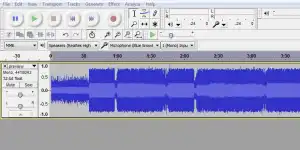
In fact, just like with a word processor, you will rely mostly on the “selector” tool. In the top toolbar, to the right of the red circle “Record” button, you will see six toolbar buttons. The top left button is your selector tool. Select it.

When you click and select a moment of time on a track and press play (space bar), it will playback the audio starting from that select point in time. If you press play again, it will stop the music and go back to where it started.
Isolating your track
Once you decide on which part of the song you want to learn, the next step is to isolate it from the rest of the track so that you can focus on it exclusively. To do this, click your mouse somewhere near the start of your song, then press the zoom icon several times until you have a real close up view of the sound waves.
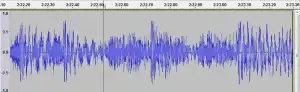
Notice how, close up, the audio is divided into a series of equally spaced humps. These humps represent the different syllables. So the zero amplitude point between two humps is actually the syllable boundary. As you get more comfortable using audacity, you will get better at identifying syllables by sight.
For the Japanese lyric in “The Flow Anthem,” I decided to start with the “Mo” syllable, so I located it on the track and placed my cursor directly behind it. After fine adjusting the cursor to the find the exact point I wanted and listening several times (left/right arrow keys and spacebar), I zoomed out and selected and deleted everything behind this point.
Now, if you press play, the playback will start exactly on that syllable.
(If this isn't playing, click “download” to get the audio. Click X at top-right of embedded audio after listening once to hear it again. Those reading this via RSS or email click through to the site to hear it)
Slowing it Down
Now that we have our track selected, our next task is to listen closely and identify each individual sound. To do this, we will need to slow down the lyrics from the normal 25-30 speech sounds per second to something much more manageable.
Usually when you slow down a track, you lower the pitch as well since you're physically stretching out the sound wave. That's how you get that clichéd “slow motion voice” effect in movies, when the actor dives to catch a falling pie or something while screaming “Nooooooo.”
Fortunately, Audacity has a special tool for slowing down the audio without altering the pitch. Highlight the whole track (double click or do select all shortcut- ctrl “A”). Then in the top menu bar, select Effects–> Change Tempo. This effect allows you to slow down or speed up the audio without effecting the pitch (The “Change Speed” effect DOES alter the pitch).
Depending on the speed of the song and my familiarity with the Flow, I typically reduce the tempo anywhere from 15-45%. Be conservative with this tool, because if you reduce the tempo too much you'll start to distort the speech sounds beyond recognition. The audio below has been reduced 35%.
Identifying the Speech Sounds: Japanese example
Here's where the fun begins. Now that it's much easier to hear each individual sound, grab a pen and piece of scrap paper and transcribe each syllable. Play one single syllable (highlight the syllable and press spacebar), write down what you hear, then move on to the next syllable.
It's a lot of trial and error, but the process itself does a lot to build your auditory sensitivity. Here's what I came up with for the Japanese line. You'll notice that I've transcribed the sounds in a way that makes sense to me. I recommend you do the same.
mo…mo…to…ni…mo…do…re…nai…za…vuh…ka…ri…no…ma…re…ma…chi…ju…wa…sku…tso…maru…van…vaw…re…hi
To confirm the syllables, play the whole lyric straight through a couple of times until you're comfortable with each one. Then, rip the paper into shreds and throw it in the garbage.
The purpose of writing down the syllables was to help you anchor the individual sounds, but now that you've completed the task, that piece of paper will only distract you. The goal here is to focus purely on developing your auditory abilities, so any brain energy you dedicate to reading is brain power diverted away from your main task.
Construction
Now that you have the syllables down, it's time to practice them in combination. To do this, you will have to group the lyrics into bite-sized chunks. In general, I separate the the songs into natural rhythmic groupings of 2-5 syllables each. After testing my techniques with over a hundred students, I've found that our brains are most comfortable with these group sizes:
For each group, listen to the audio a few times then repeat it out loud to yourself 30 times each to a steady meter (clapping, tapping or metronome).
mo…mo…to…ni…mo
do…re…nai…
za…vuh
ka…ri…no…
ma…re…ma
chi…ju…
wa…sku…tso
ma..ru…von…
vo…re…hi
Now that I'm comfy with the bite-size chunks, I group them together into the next level of rhythmic grouping and repeat the same steps.
Mo…mo…to…ni…mo…
do…re…nai…za..vu
ka…ri…no…ma…re…ma
chi..ju…wa…sku…tso
Ma…ru…von…vo…re…hi
This same process continues, but once you move beyond 8 syllable sequences, the process gets exponentially harder, because now we are moving outside of the realm of our working auditory memories, which is the compartment of our memory in which we store short sound sequences.
For example, if someone tells you his seven digit phone number all at once, you can easily replay the sound bite back in your head and enter it in your phone. But if the person throws in an area code to make it 10 digits, there's a good chance you'll need him to repeat it or break it down into chunks.
So for this phase, we have to bust out the more hardcore Audacity tricks.
Memorization:
For this task, we want to create an audio looped file for the song. I've already cut the first part of the song so that my selection starts right on that first syllable. Now I want to cut off the tail end of the audio so that I can copy and paste the tracks next to each other. Here's what I get:
It's important to keep a steady beat throughout the whole thing. As a musically-trained individual, I have a lot of experience thinking about music theoretically and thus do not have a hard time identifying the exact start and end points of a track for it to loop on beat, but for those of you who are not musically trained, you can achieve the same effect with trial and error (hint: ctrl z is the “undo” shortcut).
You'll also notice the use of the “Fade Out” effect (found under in the effects menu again). I've found this aids the memory process by delineating a clear starting point of the lyric and musical beat.
I make the loop file last about 1 minute and sing along with it over and over again until it stops. THEN I try to recall it from memory without the aid of the looped audio. This step is crucial, because the actual recall process is what does most of the work of burying this new info deep into my long-term memory. Once again, I sing the full lyric out loud to myself 30 times in a row to make sure I have it.
I then repeat the process with the next two groupings.
Then for the entire song lyric.
Finally. Back to normal speed (you can gradually build the speed too).
And there you have it, that's 36 pure Japanese rap syllables mastered in one 30 minute session. The beauty of this kind of training is that musical memory has a half-life comparable to that of plutonium, so when I'm a senile old man rocking back and forth on my front porch one day, I'll probably still be singing these lyrics to myself. Compare that to the 36 Japanese flash cards I could have studied for 2 hours and forgotten in a week.
Limitations
As mentioned before, our brains rely heavily on the existing phonetic architecture when processing foreign sounds. This means there is still a good chance that you will hear or create certain songs incorrectly, even if you listen to it several times. This is especially true for foreign language sounds that you have never heard before.
Japanese is simple phonetically, but the Russian and Swahili definitely had a few sounds that were new to me. With my phonetics and linguistics training, it's easy for me to read Wikipedia's “Russian phonology” page or “Swahili Phonology” page and develop a what knowledge of all the possible sounds in these languages, but I won't be able to appreciate these differences overnight. So I am sure that I made a few errors.
Rethinking teaching models
Using audacity to break down and teach yourself songs is an extremely helpful process, but there's a lot of time spent on editing and other technical tasks that do nothing for your language skills. Also, as mentioned above, you can never be sure if what you're singing or rapping is 100% correct without someone telling you.
This is where a trained teacher can be very useful. For my Mimic Method Students, I create the audio materials for learning the songs, they use the materials and learn the songs at their own pace, then they submit recordings of themselves singing the songs. I then give them precise feedback on each sound they mispronounce. Now that they have the main part of the song memorized and don't have to think about it, fixing the few errors here and there is easy.
But as I always tell my students: I do NOT teach language. You don't learn language in class, you learn language in the real world, listening to and mimicking real native sounds. I'm just a sound consultant who can guide you along the path to Flow and Fluency. I can't teach you how to speak Spanish/Portuguese/or Chinese anymore than I can teach you how to ride a bike. Sure, I can hold the handlebars for you while you try to get your balance, but ultimately, it's up to you to just do it.
Social